在我們離開決策樹之後,我們要進到SVM了!SVM的中文全名叫做支援向量機!
我們在兩組資料間,可以找到一條分界來對資料進行分界,而SVM利用了Kernel函數來找到這條線(平面)!
(詳細的算式推倒這裡沒有ˊˇˋ,這裡只是簡單介紹一下他們是啥?在幹什麼?)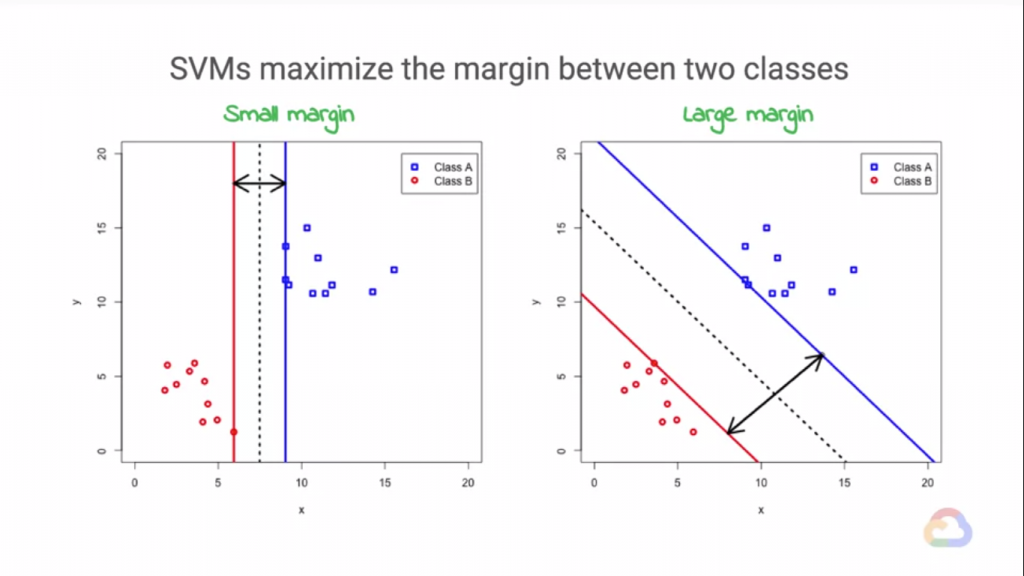
在一般的分類問題中,我們在一組資料裡,如果向上圖這樣可以被分成兩類,我們都可以找到一條"最適合"的分界線來
界線他們!
而找到這條線其實不難,我們在之前的文章其實也有提過一些找到這條界線的方法,那麼Kernel函數到底在這種找界線的問題起到了甚麼作用呢?我們可以看到上圖,在決策線與資料的距離我們稱之為"決策邊界",我們都知道我們不可能蒐集到"大量"到可以直接回歸出不會出錯的模型,這代表我們的模型都會出錯,更直觀的說,我們找到的這條決策界線
其實沒有完全把資料分成兩邊,就算在測試資料看起來已經完美地把資料界線了,不過實際在預測時我們就會發現其實沒有,那麼既然無法蒐集到可以回歸出"現實世界真理"(噗)的資料量,那麼我們能做的就是降低錯誤率。
將低錯誤率其實也不難,我們剛剛提到決策界線到資料的距離稱為決策邊界!我們如果要嘗試降低錯誤率,
試著擴大決策邊界,會使我們的模型在預測新的資料時有更好的支持!而放大這個決策邊界的方法我們以"Kernel函數"
為基礎,創建出了SVM!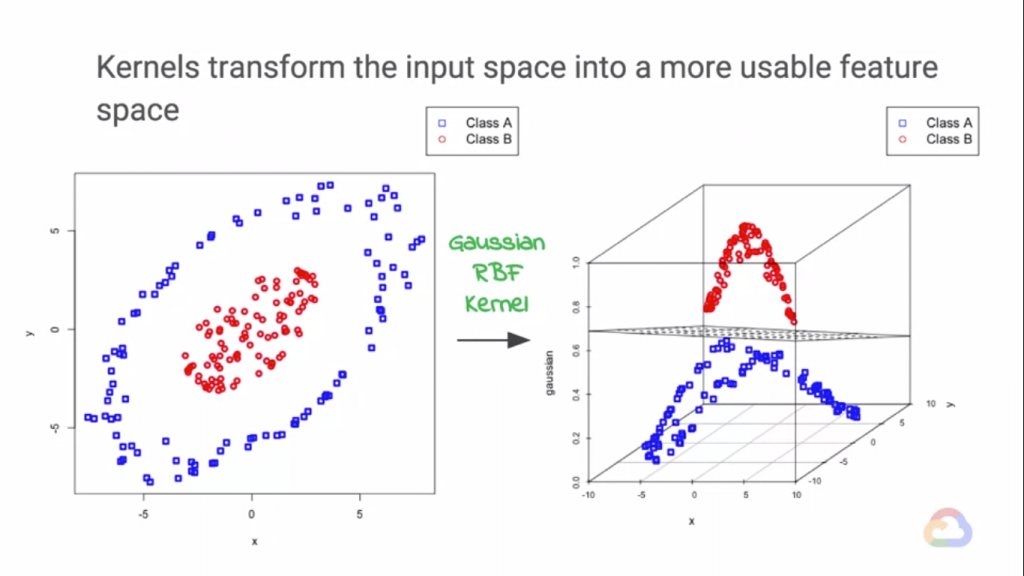
SVM的作法很簡單!我們透過Kernel函數,把二維的資料映射到三維資料!這麼一來,我們只要找到一個間單的平面就可
以把兩組資料分開!而我們剛剛所謂的"決策邊界"也會得到優化!這就是Kernel函數和SVM運作的方法。

